← ブログに戻る
チュートリアル2026年6月4日by K.hirano
gemma4:12bはollamaで動かない — 12GB GPUでllama.cpp実測52t/sの最短ルート
ollamaのHTTP 500やSIGFPEで詰まるgemma4:12bを、llama.cpp経由で12GB GPUに載せる実測手順と判断材料をまとめました。
#gemma4#ollama#llama.cpp#gpu#tutorial
TL;DR: gemma4:12b が ollama で動かないのは上流バグであなたのせいではない。本家 llama.cpp の docker なら 12GB GPU でも実測 52t/s で今日動く(実コマンド掲載)。ただし日本語長文の品質は上流の安定化待ち。(2026-06-04 続報: ollama 0.30.4 正式版で再検証。公式配布は macOS 専用のままだが、テキストのみの回避策で ollama でも 52t/s を確認 → 続報節へ)(2026-06-05 続報: ollama 0.30.5 で全部直りました。公式タグ gemma4:12b が Linux にも配布開始・SIGFPE 修正・GGUF 再変換で日本語も正常。回避策は不要になりました → 詳細は Bloggemma4:12bがollamaで直った — 0.30.5で3層バグ全解消を実測確認【回避策は不要に】gemma4:12bのSIGFPE、macOS専用配布、日本語崩れを同一環境で実測。ollama 0.30.5で何が直り、何を捨ててよいかを整理します。→と本記事の続報2節へ)
Bloggemma4:12bがollamaで直った — 0.30.5で3層バグ全解消を実測確認【回避策は不要に】gemma4:12bのSIGFPE、macOS専用配布、日本語崩れを同一環境で実測。ollama 0.30.5で何が直り、何を捨ててよいかを整理します。→と本記事の続報2節へ)
関連記事としては  BlogOllama導入の罠と解決手順——GPU認識・日本語チャットまでの全記録と結論RTX 4070 Ti搭載の自宅サーバーにOllamaをSSHでセットアップした実録。非対話環境でのインストール罠、バイナリ直接DL、systemdサービス化、qwen2.5:7bでの日本語チャットまで。→ もあわせて読むと、今回の論点とのつながりを把握しやすくなります。
BlogOllama導入の罠と解決手順——GPU認識・日本語チャットまでの全記録と結論RTX 4070 Ti搭載の自宅サーバーにOllamaをSSHでセットアップした実録。非対話環境でのインストール罠、バイナリ直接DL、systemdサービス化、qwen2.5:7bでの日本語チャットまで。→ もあわせて読むと、今回の論点とのつながりを把握しやすくなります。
先に結論を書きます。gemma4:12b は 2026-06-04 時点で ollama では動きません。これはあなたの環境のせいではないです。
一方で、本家 llama.cpp の docker 経由なら 12GB GPU でも実際に動き、私の環境では 52t/s まで出ました。 ただし、日本語長文の品質はまだ安定化待ちです。ここは期待を上げすぎない方がいいです。
この記事では、ollama の上流バグを切り分けたうえで、今日動かすための最短ルートをそのまま共有します。
この記事で検証した内容
| 検証項目 | 環境 | 結果 |
|---|---|---|
| ollama で gemma4:12b が動くか | RunPod RTX A4000・4回実走 | ❌ pull 412 / generate SIGFPE(上流バグ → のちに 0.30.5 で解消・続報節へ) |
| llama.cpp docker で動くか | 12GB GPU(RTX 4070 Ti) | ✅ 実測 52t/s |
| 日本語長文の品質 | 実プロンプトで確認 | 🟡 day-one ビルドは崩れあり → GGUF 再変換で後日解消 |
| 詰まりやすいポイント | 実ログから切り分け | ✅ 4 つを本文に掲載 |
ollama の復旧を前提にした回避策探しや、日本語品質を過大評価したおすすめはしません。検証した範囲だけを書きます。
まず結論: ollama は現時点で外れ、llama.cpp なら今日動く
2026-06-04 時点の実測では、gemma4:12b は ollama で以下のどちらかに当たります。
- 安定版 v0.30.3 では pull が 412 に落ちる
- 0.30.4-rc0 / rc1 では pull 後に generate で SIGFPE
RunPod の RTX A4000 で 4 回実走して確認しました。量子化やフラグをいじっても直りません。これは自分の環境の問題ではなく、上流コード側のバグとして扱うのが妥当です。
だから、いま必要なのは「ollama を頑張ること」ではなく、別のランタイムに逃がして今日使える状態を作ることです。
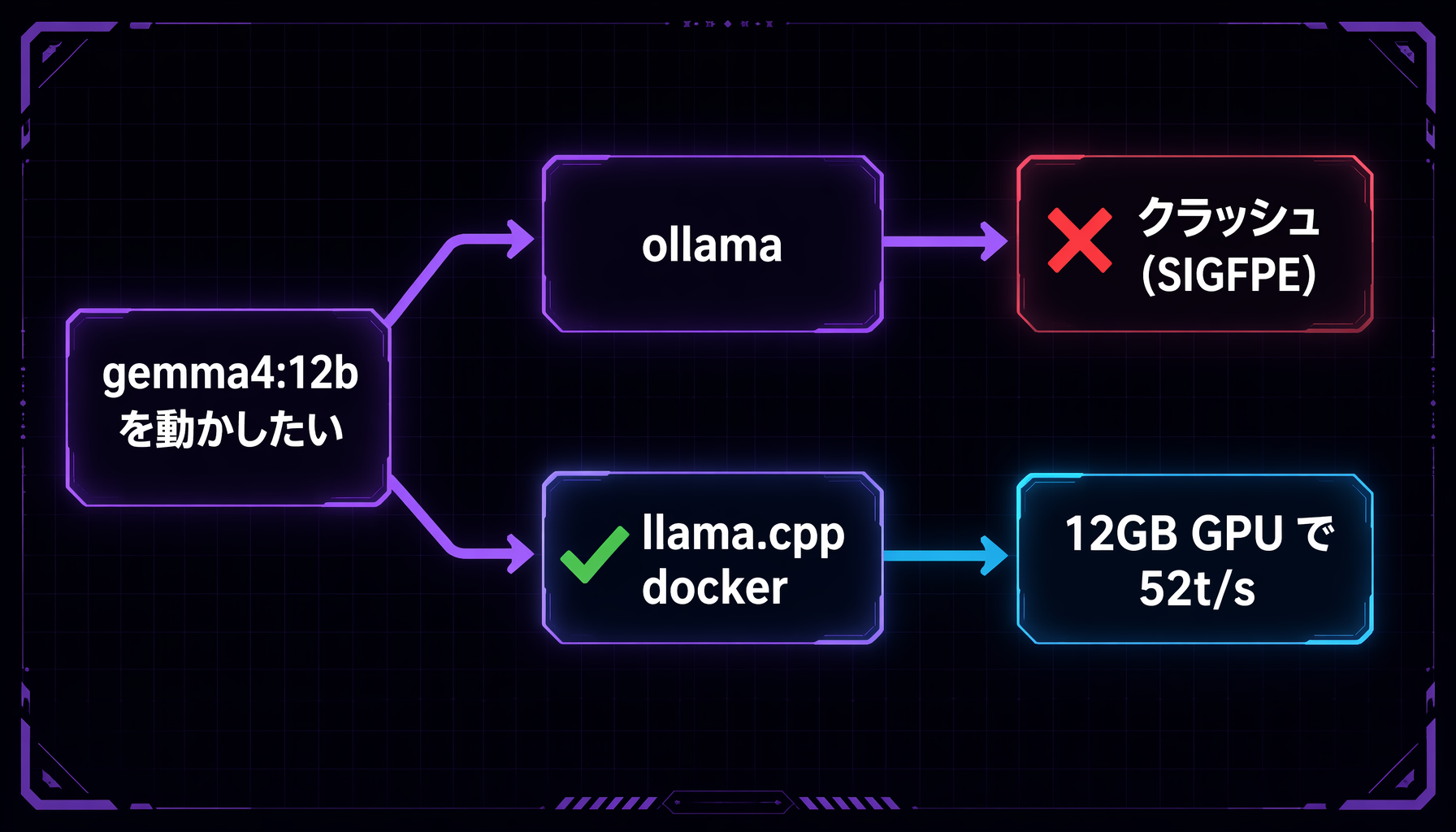
gemma4:12b の最短ルート: ollama は上流バグで外れ、llama.cpp なら今日動く
ランタイム対応マップ(2026-06-05 更新)
| ランタイム | 状態 | 備考 |
|---|---|---|
| ollama ★実測 | ✅ 動く(0.30.5〜) | 公式タグ gemma4:12b を 4070Ti で実測 52t/s・VRAM 8.1GB・日本語正常。思考モデルのため think:false 必須。0.30.4 以前は SIGFPE(経緯 → 続報節) |
| llama.cpp ★実測 | 🟡 テキストのみ動く | --no-mmproj 必須(vision は未対応) |
| HF Transformers | ✅ 動くはず | 公式サポートの本命(公式情報ベース・未実測) |
| MLX | ✅ 動くはず | Apple Silicon 向け(公式情報ベース・未実測) |
| LM Studio | 🟡 条件付き | エンジン更新の取り込み待ちあり(報告ベース・未実測) |
| vLLM | 🟡 条件付き | day-one 対応は要バージョン確認(報告ベース・未実測) |
★実測 = 本記事で実際に検証した行です。それ以外は 2026-06-04 時点の公式情報・コミュニティ報告ベースなので、最新状況は各プロジェクトのリリースノートをご確認ください。
この記事で扱うのは、NVIDIA GPU で最も手軽に動く llama.cpp 経路です。
最短ルートはこれ: llama.cpp の docker で gemma4:12b を直接読む
使うのは本家の docker イメージです。
- イメージ:
ghcr.io/ggml-org/llama.cpp:server-cuda - モデル:
-hf ggml-org/gemma-4-12B-it-GGUF:Q4_K_M - 重要な回避策:
--no-mmproj
Q4_K_M は 7.4GB なので、16GB はもちろん、12GB GPU にも収まります。 私の実測では VRAM 9.0GB / 12GB でした。カタログ値より少し地味ですが、実際にはこの「地味に収まる」が大事です。
実行コマンド
bash
docker run --gpus all --rm -it \
-p 8080:8080 \
ghcr.io/ggml-org/llama.cpp:server-cuda \
-hf ggml-org/gemma-4-12B-it-GGUF:Q4_K_M \
--host 0.0.0.0 \
--port 8080 \
--no-mmproj \
--ctx-size 8192 \
--reasoning-budget 0 \
--repeat-penalty 1.1 \
--repeat-last-n 64
このコマンドの意味
-hf ...: Hugging Face からモデルを取得します--no-mmproj: vision projector を読ませないための回避策です--ctx-size 8192: コンテキストを抑えて KVキャッシュの膨張を防ぎます。これを外すと 12GB に収まらない可能性があります(実測 VRAM 9.0GB はこの設定での値です)--reasoning-budget 0: 思考出力に流れて本文が空になる事故を避けます--repeat-penalty 1.1/--repeat-last-n 64: 日本語長文の無限ループ対策です
ここで一度、足元を見ておきます
gemma4 はテキストだけのモデルとして扱うなら、vision 機能を無効化した方がむしろ安定します。
ここを外すと、導入したのに server が落ちる、あるいは 502 が延々出る、というやや嫌な流れになります。導入直後は「壊れている」のではなく、まだモデルをダウンロード中というケースも多いので、そこも切り分けが必要です。
詰まりポイント1: --no-mmproj は必須
gemma4 の vision projector は gemma4uv 形式ですが、2026-06-04 時点では llama.cpp 側が未対応です。
何が起きるかというと、-hf が自動で落としてきた mmproj を読み込む段階で、こうなります。
text
unknown projector type: gemma4uv
そのまま server が終了し、フロント側では 502 が続きます。
回避策
テキスト用途なら mmproj を読ませないことです。
bash
--no-mmproj
これだけでいいです。vision を使いたい人には少し残念ですが、現時点ではそこを欲張ると先に進めません。
詰まりポイント2: 起動直後の 502 は失敗ではなくダウンロード待ち
llama.cpp の -hf は、モデルのダウンロードが先、listen が後です。
つまり、起動してすぐに 502 が返ってきても、必ずしも壊れているわけではありません。モデル本体が 8GB 前後あるので、初回は普通に時間がかかります。
ollama だと「pull が終わってから動く」感覚が強いので、ここで fail-fast に判断すると、少し誤診しやすいです。
確認ポイント
docker logsに download の進行が出ているかcurl http://localhost:8080/v1/modelsが後で通るか- しばらく待っても
unknown projector typeが出ていないか
詰まりポイント3: 日本語長文は repeat-penalty を入れないと壊れる
実機で触っていて、ここで手が止まりました。少なくとも私の環境では、repeat-penalty を外すと、長文日本語で無限ループが出ました。
具体的には、意 意 意... のような反復が伸びて、8000 トークン級まで暴走する実例を観測しています。
直し方
bash
--repeat-penalty 1.1 --repeat-last-n 64
これを入れると、対照実験で同じ 2 問が 799 / 1036 トークンで正常終了しました。
ollama は既定でこのあたりが効いているので、普段 ollama で触っている人ほど気づきにくい差分です。
詰まりポイント4: reasoning が本文を飲み込むことがある
gemma4 は思考モデルです。なので、出力が reasoning_content 側に流れることがあります。
max_tokens が小さいと、本文が空っぽに見えることもあります。これ、初見だとかなり嫌です。
回避策
瞬時回答が欲しいなら、reasoning を切ります。
bash
--reasoning-budget 0
また、/completion ではなく /v1/chat/completions を使ってください。raw 系のエンドポイントだとチャットテンプレートが効かず、出力が崩れやすいです。
実測速度: 12GB でも 52t/s まで出た
速度はかなり良かったです。
- RunPod RTX A4000 16GB: 44.77 tokens/s(100% GPU)
- 自宅 RTX 4070 Ti 12GB: 52.4 tokens/s
この数字は、いつも使っている予測式でも筋が通っています。
生成速度(tokens/s) ≒ GPUメモリ帯域(GB/s) ÷ モデルサイズ(GB) × 効率(0.6〜0.85)
A4000(帯域 448GB/s)なら理論値は 448 ÷ 7.4 ≒ 60 tokens/s。実測 44.77 は効率75%でほぼ式どおりです。LLM の文章生成はメモリ帯域律速なので、モデルが VRAM に収まってさえいれば素直にこの式に乗ります。12B 級は 12GB でも体感即時です。
ちなみにこの式と「VRAM にあふれた瞬間の崖」については、 BlogRunPodでGPUを時給39円で借りて実測 — 安い16GBが7.5倍割高だった結論RunPodでgemma3:27bを16GBと24GBで実測。借りるのは簡単でも、安いGPUが得とは限らない理由を数字で整理します。→で詳しく検証しています。
BlogRunPodでGPUを時給39円で借りて実測 — 安い16GBが7.5倍割高だった結論RunPodでgemma3:27bを16GBと24GBで実測。借りるのは簡単でも、安いGPUが得とは限らない理由を数字で整理します。→で詳しく検証しています。
ここは大げさに言うより、「普通に速い」と受け取る方が実態に近いです。
24問テストは 173/240 だったが、主役ではない
品質評価も一応しました。
- 173/240
- 72.1%
- ランクB
内訳を見ると、論理 52/60、コード 52/60 はかなり良いです。なので、モデルの地力が低いわけではないです。
一方で、日本語長文では
- 分かち書きの崩れ
- 固有名詞の崩れ
- 例: 「松尾芭蕉」が「松尾芭人」になる
といった、日常運用では気になる揺れが残りました。
ここは day-one ビルドの成熟度の問題 と見るのが自然です。モデルの知能そのものを否定する材料ではありません。
続報: ollama 0.30.4 正式版で再検証した(2026-06-04)
公開直後に ollama 0.30.4 正式版が出たので、自宅の RTX 4070 Ti 12GB で即日再検証しました。結論から言うと、「そのまま」はまだ動きません。ただし回避策なら動いて、52.25t/s 出ました。
動かない原因は 1 つではなく、3 層に分かれていました。
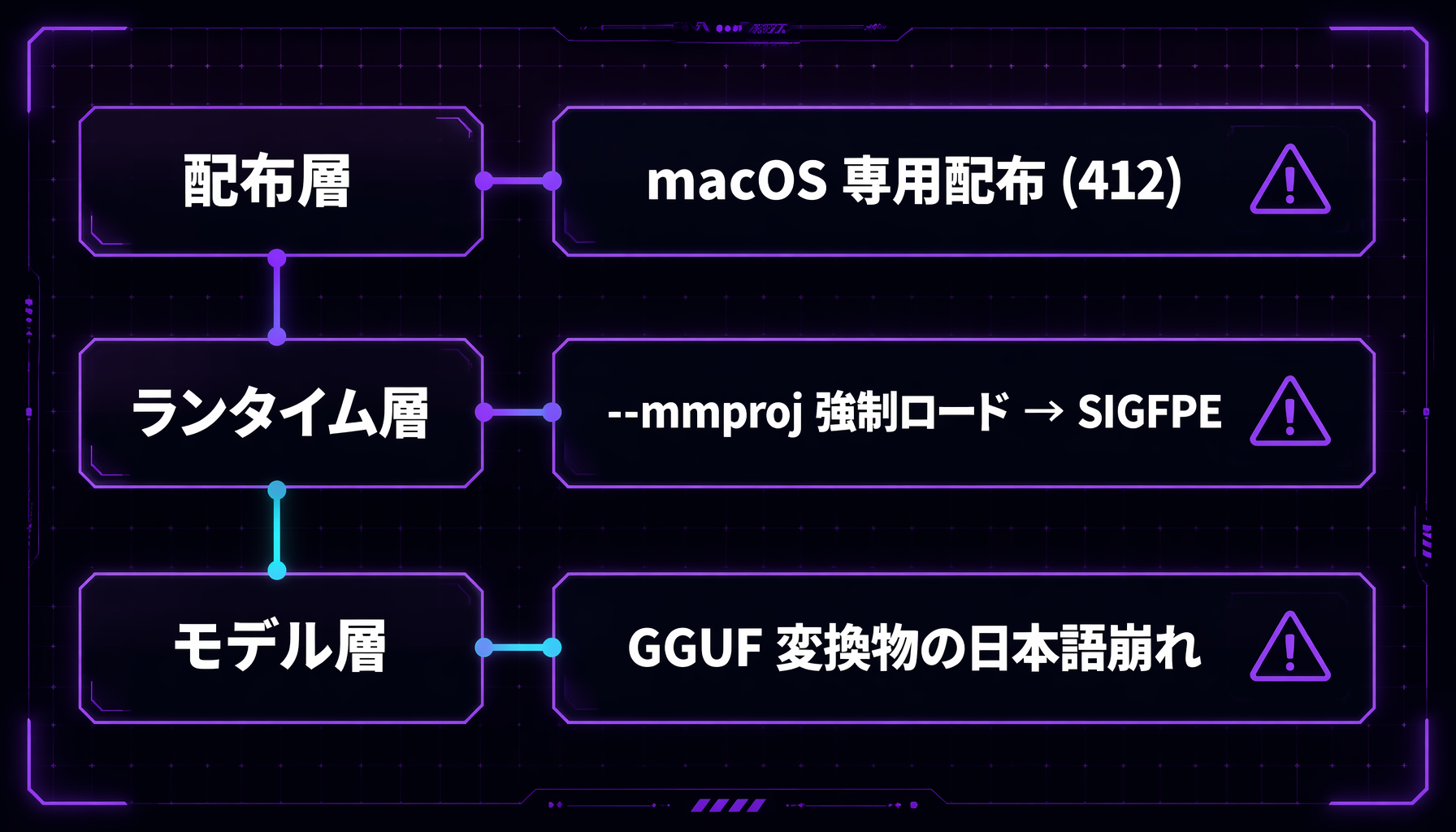
「動かない」の正体は1つではない: 配布・ランタイム・モデルの3層で別々の問題
| 層 | 何が起きるか | 切り分け結果 |
|---|---|---|
| 配布 | ollama pull gemma4:12b が manifest not found | 素の 12b タグはそもそも存在しない。12b 系タグ(mlx / mxfp8 / nvfp4)は全て 412: this model requires macOS = macOS 専用配布 |
| ランタイム | HF から GGUF を直 pull すると generate で SIGFPE | ログを見ると ollama が llama-server に --mmproj を強制付与していた。詰まりポイント1(gemma4uv 未対応)と同じ罠で、ollama 側に外すオプションがない |
| モデル | 日本語長文が崩れる | 後述。これだけは回避できない |
回避策: テキスト blob だけの Modelfile を作る
mmproj を読ませなければ動きます。pull 済みのテキスト用 GGUF blob だけを FROM に指定したモデルを作ってください。
bash
ollama pull hf.co/ggml-org/gemma-4-12B-it-GGUF:Q4_K_M
# ↑ この時点で generate はまだ SIGFPE で落ちるが、blob のダウンロードは完了している
# テキスト blob のパスを確認(一番大きい 7.4GB のファイルがそれ)
ls -lhS ~/.ollama/models/blobs | head -3
echo 'FROM /home/<ユーザー名>/.ollama/models/blobs/<7.4GBのblob名>' > Modelfile
ollama create gemma4-12b-text -f Modelfile
blob はハッシュで再利用されるので、追加のディスク消費はほぼゼロです。これで ollama run gemma4-12b-text が普通に動きます。思考出力で本文が空に見えるときは、API なら "think": false を付けてください。
実測: 52.25t/s・100% GPU
- RTX 4070 Ti 12GB: 52.25 tokens/s(VRAM 8.0GB・100% GPU)
- 同じ GPU での llama.cpp 実測が 52.4t/s なので、ランタイム間の速度差は実質ゼロでした
ただし日本語崩れは直っていない
ここが残念なところです。temperature 0 で「日本の四季について説明して」と聞くと、「三千島」という存在しない固有名詞の説明が返ってきました(/api/generate と /api/chat の両方で同一出力)。
ただ、これで切り分けは一歩進みました。同じ GGUF を別ビルドのランタイムに載せても、崩れ方が同じ。つまり崩れの原因はランタイムではなく、GGUF 変換物そのものです。上流で GGUF が再変換されるまで、日本語の常用は待ちです。
続報2: ollama 0.30.5 で全部直った(2026-06-05)
前日の3層切り分けから半日で、上流が一気に動きました。3層すべてに修正が入っています。
| 層 | 何が直ったか | 確認結果(4070Ti 実機) |
|---|---|---|
| 配布 | 公式タグ gemma4:12b(7.6GB)が Linux にも配布開始 | ollama pull gemma4:12b 成功 |
| ランタイム | v0.30.5 リリースノートに「Fix gemma4:12b floating point exception crash」 | SIGFPE 消滅・正常生成 |
| モデル | ggml-org の GGUF が再変換(2026-06-04 15:42 UTC) | 同一質問・temperature 0 で「三千島」幻覚が消え、桜・お花見・入道雲と正しい構造化日本語に |
実測は 52.2〜52.7t/s・VRAM 8.1GB・100% GPU。回避策版と同速=移行コストなしです。
bash
# 0.30.5 以降はこれだけで動きます
ollama pull gemma4:12b
curl localhost:11434/api/chat -d '{"model":"gemma4:12b","messages":[{"role":"user","content":"こんにちは"}],"think":false,"stream":false}'
残る注意は1点だけ。gemma4 は思考モデルなので、think: false を付けないと応答が空に見えます(出力が thinking 側へ流れるため)。
上の回避策(テキスト blob Modelfile)と llama.cpp 迂回の手順は、0.30.4 以前を使い続ける場合の参考として残します。
いまの使い分け: 何を選ぶべきか
2026-06-05 時点では、こう考えるのがいちばん実務的です。
- ふつうに使いたい → ollama 0.30.5 + 公式タグ
gemma4:12bで OK(think:falseだけ忘れずに) - コード・英語・日本語とも → 実用圏に入りました(同一質問の temp0 比較で日本語修復を確認済み)
- 0.30.4 以前から更新できない事情がある → テキストのみ Modelfile の回避策(上の続報節)で
- 軽さ優先・省VRAM → gemma4:e4b も引き続き良い選択(
 BlogGemma 4 E2B vs E4B:24問実測で見えた速度5倍差の使い分け基準Gemma 4 E2B(2B)とE4B(4B)を24問実測比較。スコア差9%・速度差5倍の実態と、VRAM 4GBで動く省電力LLMとして選ぶべき条件を整理。→)
BlogGemma 4 E2B vs E4B:24問実測で見えた速度5倍差の使い分け基準Gemma 4 E2B(2B)とE4B(4B)を24問実測比較。スコア差9%・速度差5倍の実態と、VRAM 4GBで動く省電力LLMとして選ぶべき条件を整理。→)
念のため添えると、これは「12b が e4b より劣る」という話ではありません。計測経路が違ううえ(e4b は ollama・12b は出たての llama.cpp ビルド)、12b の失点の大半は day-one ビルドの文字崩れです。地力は 12b が上、今日の安定は e4b という時点付きの使い分けです。
ollama 正式版(0.30.4)での再挑戦は、上の続報節に書いたとおりです。あとは tokenizer まわり=GGUF の再変換が上流で入れば、状況は一気に変わるはずです。
いま取るべき行動
読者が次にやることは、だいたいこの 3 つです。
- ollama 側で詰まっているなら、環境切り分けをやめて上流バグとして扱う
- llama.cpp の docker で 12GB GPU に載るか試す
- 日本語品質はその場で判断し、常用するかは保留する
もしチーム内で共有するなら、
ollama では現時点で SIGFPE / 412 で止まるllama.cpp の docker なら 12GB でも動くただし日本語長文の安定運用はまだ待ち
この 3 行で十分です。盛らない方が後で揉めません。
動作確認の最終チェック
起動後、最低限ここまで確認してください。
bash
curl http://localhost:8080/v1/models
応答が返れば、次に chat API を叩きます。
bash
curl http://localhost:8080/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "gemma-4-12B-it-GGUF:Q4_K_M",
"messages": [
{"role": "user", "content": "日本語で一文だけ返して"}
],
"max_tokens": 64
}'
ここで短い日本語が返れば、最低限の導入は成功です。
まとめ
gemma4:12b は、2026-06-04 時点では ollama で動きません。これはあなたのせいではありません。
本家 llama.cpp の docker 経由なら、12GB GPU でも実測 52t/s で動きます。 ただし、日本語長文の品質はまだ安定化待ちです。
今は「ollama を直す」より「今日使える経路へ逃がす」が正解です。正式版対応が来たら、そこでまた戻せばいい。実際、0.30.4 正式版は出た当日に再検証しました(結果は続報節へ)。次は GGUF の再変換待ちです。
注意点・制約
- OS・ライブラリのバージョンが異なると手順が変わる場合があります。
- クラウドサービスは設定UIが更新されることがあり、画面が本記事と異なる可能性があります。
- 本番環境への適用前にテスト環境で動作を確認してください。
どのように検証したか
- 記事の手順を実際に実行して動作を確認しています。
- コマンドの出力例は実際の実行結果を掲載しています。
よくある質問
手順通りに進めても動かない場合は?
エラーメッセージをそのままコピーして検索すると解決策が見つかることが多いです。バージョン違いが原因のケースも多いため、前提条件を再確認してください。
どのOSで動作確認していますか?
記事内に記載の環境で確認しています。他のOSでの差異は適宜読み替えてください。
参考リンク
- BlogGemma 4 E2B vs E4B:24問実測で見えた速度5倍差の使い分け基準Gemma 4 E2B(2B)とE4B(4B)を24問実測比較。スコア差9%・速度差5倍の実態と、VRAM 4GBで動く省電力LLMとして選ぶべき条件を整理。→
- BlogRunPodでGPUを時給39円で借りて実測 — 安い16GBが7.5倍割高だった結論RunPodでgemma3:27bを16GBと24GBで実測。借りるのは簡単でも、安いGPUが得とは限らない理由を数字で整理します。→
- META-MARK
この記事を書いた人
HW系エンジニアとして20年以上、10,000件を超える顧客訪問と2,000件を超える単独ソリューション実績があります。AIツールを使った個人開発や IoT 農園、Raspberry Pi を使ったオートメーション化なども実践中です。エンジニア専門結婚相談所も運営しています。ClaudeCode で解決できない心の課題も、現場目線で一緒にほどいていきます。
関連記事
- BlogOllama導入の罠と解決手順——GPU認識・日本語チャットまでの全記録と結論RTX 4070 Ti搭載の自宅サーバーにOllamaをSSHでセットアップした実録。非対話環境でのインストール罠、バイナリ直接DL、systemdサービス化、qwen2.5:7bでの日本語チャットまで。→
 BlogiGPU で LLM 推論:Radeon 780M + Ollama ROCm の速度実測と落とし穴3つRadeon 780MでOllama ROCmを動かす手順を、renderグループ・gfx1103偽装・OOMの3つの落とし穴ごとに整理。Ubuntu 24.04向けの実用ガイドです。→
BlogiGPU で LLM 推論:Radeon 780M + Ollama ROCm の速度実測と落とし穴3つRadeon 780MでOllama ROCmを動かす手順を、renderグループ・gfx1103偽装・OOMの3つの落とし穴ごとに整理。Ubuntu 24.04向けの実用ガイドです。→- Bloggemma4:12bがollamaで直った — 0.30.5で3層バグ全解消を実測確認【回避策は不要に】gemma4:12bのSIGFPE、macOS専用配布、日本語崩れを同一環境で実測。ollama 0.30.5で何が直り、何を捨ててよいかを整理します。→
関連リンク
- 実際の構成を探すなら、GPU 比較ページやローカルLLM向け構成記事もあわせて見ると判断しやすいです。
- ハードウェア候補は用途別の AI 構成ガイドからたどると、単体製品より違和感なく検討できます。
記事内で紹介した製品
META-MARK × AI
ローカルAIを動かすGPU、ちゃんと選べていますか?
VRAM・性能・コスパをMetaScoreで数値化。AIアプリ別の推奨ハードウェア要件も確認できます。