← ブログに戻る
開発ログ2026年6月9日by K.hirano
Fable 5 は正解集のバグを見つけて、りんご問題で転んだ——24問実測レポート
Claude Fable 5 を24問で実測。224点でHaiku 4.5(221点)を僅差で上回るが、中身は別物でした。正解集のバグ発見とA4誤答まで公開します。
#claude#benchmark#dev-log#ai検証
TL;DR: Fable 5 は24問テストで 224/240(Rank S)——Haiku 4.5(221/240)をわずか3点上回る単独トップ。ただし差は採点誤差の範囲内で、中身は別物で、Haiku が崩れた最難問B6を完答し、2ヶ月誰も気づかなかった正解集のバグまで発見した。一方で A4(りんご)では Haiku と同じ「自信満々の誤答」。総点では質の差は見えないし、最上位モデルでも直感バイアスは消えない
目次
- Fable 5 は正解集のバグを見つけて、りんご問題で転んだ——24問実測レポート
- 発表概要:Fable 5 は Opus 4.8 の上に出た新最上位ティア
- 24問ベンチの結論:224点で単独トップ、でも Haiku 4.5 とは誤差範囲
- ここは見せ場です:B6 を完答し、決定木の筋まで通した
- C6 で正解集のバグを発見:Fable 5 が正しかった
- A4 のりんご問題で転ぶ:最上位モデルでも直感バイアスは残る
- 採点官のブレもそのまま書く:224 と 229 の差は誤差範囲
- どのように検証したか
- 24問ベンチマークの見え方は、僅差でもまるで違う
- 参考になる比較:24問解説、Haiku+Advisor、Bonsai-8B
- よくある質問
- 参考リンク
- まとめ:Fable 5 は「僅差なのに別物」だった
- 注意点・制約
- この記事を書いた人
- 関連記事
Claude Fable 5 が出ました。読者がまず知りたいのは、たぶんここだと思います。Opus 4.8 から乗り換える価値があるのか。そして、公式ベンチの数字だけで判断していいのか。料金は Opus の2倍ですし、6/22 までの無料期間内に触るべきか迷う。ここはかなり現実的な悩みです。
先に結論を書きます。Fable 5 は24問テストで 224/240(Rank S)でした。Haiku 4.5(221/240)をわずか3点上回る単独トップですが、この差は採点誤差の範囲内です。 ただし中身はかなり違いました。Fable 5 は、Haiku が崩れた最難問を完答し、さらに2ヶ月近く誰も気づかなかった正解集のバグまで見つけました。一方で、りんご問題では Haiku と同じ誤答をしました。
つまり、総点だけでは質の差が見えません。 そして、最上位モデルでも直感バイアスは消えない。これが今回いちばん大きい発見です。
発表概要:Fable 5 は Opus 4.8 の上に出た新最上位ティア
2026-06-09 に Claude Fable 5 / Claude Mythos 5 が同時発表されました。Fable 5 は Opus 4.8 の上に置かれる新しい最上位ティアです。公式説明では、Fable と Mythos の違いはモデルそのものというよりセーフガードです。該当リクエストは Opus 4.8 にフォールバックし、95%超のセッションではフォールバックなしとされています。
2026-06-10 時点の提供条件も押さえておきます。
- API 料金: 入力 $10 / 出力 $50 per MTok
- Opus 4.8 のちょうど2倍
- Batch は半額、キャッシュ読みは90%引き
- 1M コンテキストが標準、最大出力 128K
- 6/9〜6/22 は Pro / Max / Team / Enterprise に追加費用なしで含まれる
- 6/23 以降は usage credits が必要
発表時点の説明としては、かなり攻めた価格設定です。だからこそ、実務で本当に差があるのかを見たかったわけです。
24問ベンチの結論:224点で単独トップ、でも Haiku 4.5 とは誤差範囲
まず全体の比較です。今回のテストは、24問をカテゴリ別に採点した自己ベンチマークです。Fable 5 は 224/240、Haiku 4.5 は 221/240 でした。
| モデル | A | B | C | D | 合計 |
|---|---|---|---|---|---|
| Fable 5 | 47 | 60 | 60 | 57 | 224 |
| Haiku 4.5 | 52 | 55 | 57 | 57 | 221 |
| gemma4:12b | - | - | - | - | 173 |
| Bonsai-8B | - | - | - | - | 98 |
数字だけ見ると「ほぼ並んでいる」ように見えます。ですが、中身はまったく別物でした。
- Fable 5 は B と C を満点にしました
- Haiku 4.5 は B で崩れました
- ただし Fable 5 は A で取りこぼしました
- そして A4 のりんご問題では、Haiku と同じ誤答をしました
ここが重要です。総点ベンチマークは、強いモデル同士の質の差を隠します。 224 点という見出しは立派ですが、それだけでは現場の判断材料として足りません。
ここは見せ場です:B6 を完答し、決定木の筋まで通した
最も印象に残ったのは B6 です。12枚の偽コインを天秤3回で見つける問題で、Haiku 4.5 は決定木が自己矛盾して失点しました。Fable 5 はそこをきれいに通しました。
Fable 5 の回答は、1回目に「1,2,3,4 vs 5,6,7,8」、2回目に混ぜ替えて「1,2,5 vs 3,4,6」という流れを構築し、3^3 = 27 > 24 という情報量の根拠まで説明しました。単に当てにいったというより、問題の制約を見て解法の骨格から組み立てた感じです。
はい、これは最高峰モデルと言っていいでしょう。少なくとも、論理系の筋の通し方はかなり強いです。
C6 で正解集のバグを発見:Fable 5 が正しかった
今回いちばん実務的に価値があったのは、ここでした。
C6 はメール正規表現の問題です。旧正解集では「4,5,6 がマッチしない」としていましたが、Fable 5 が「[email protected] はマッチする」と指摘しました。理由は明快で、正規表現
python
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$
の [a-zA-Z0-9.-]+ に . が含まれるためです。[email protected] はこの部分に一致します。
そこで Python re で実機再検証したところ、Fable 5 が正しかった です。マッチしないのは 5,6 のみでした。
このバグ、2026-05-20 の復元以来、2ヶ月近く誰も気づいていませんでした。 正解集は訂正済みで、Haiku の過去スコアも Issue #50 で再判定し、C6 を 10→7点に修正しました(合計 224→221)。
これは「モデルが賢かった」だけで終わる話ではありません。LLM を採点補助に使うと、正解集そのものが壊れていても通ってしまう。今回の発見は、その危うさを実例で示しました。
A4 のりんご問題で転ぶ:最上位モデルでも直感バイアスは残る
一方で、最重要発見もありました。A4 の「りんごを取った」問題です。
Fable 5 は、Haiku 4.5 とまったく同じ誤答を出しました。
- 問題文の「取った」を素直に捉えすぎる
- 文脈上は「花子が持っている」とは断定できない
- 正解は「4. わからない」
つまり、自信満々に間違える問題は最上位モデルでも残る ということです。これは Haiku+Advisor 記事の続編として見ると分かりやすいです。Advisor を足してもすり抜けるタイプの誤答は、モデルを上げても完全には消えません。
期待したくなる気持ちは分かります。ですが、ここは足元を見ておくべきです。高いモデルは、曖昧文の直感バイアスを自動で消してくれるわけではない。この点はかなり重要です。
採点官のブレもそのまま書く:224 と 229 の差は誤差範囲
正直、ここは少し迷いました。というのは、同じ誤答に対して採点がぶれるからです。
A4 の同一誤答について、Haiku 時の採点は 5点、今回の Fable 5 は 0点でした。つまり、LLM 採点には**±5点程度の判定ブレ**があります。
このため、Fable 5 の 224/240 と、A4 を Haiku 基準で採点し直したときの 229/240 の差は、厳密には誤差範囲と見るべきです。
ここで一度、足元を見ておきます。24問ベンチは便利ですが、1〜2問の採点ブレで印象が変わることがあります。だから、順位よりも「どの問題で、どんな崩れ方をしたか」を見たほうが実務には役立ちます。
どのように検証したか
今回の検証条件は透明にしておきます。
- テスト日: 2026-06-10
- Claude Code の Agent ツールを使用
model:"fable"のサブエージェントを24問並列起動- 各問は独立コンテキスト
- ツール使用は禁止
- オーケストレーター自身も Fable 5 を使用した自己ベンチマーク構成
- 採点官は前例と同じ Sonnet の Agent ツール
- C6 のみ Python
reで実機再検証 - ルールベース採点は使っていない
- 結果正本:
data/benchmark-results/fable-5-20260610.json
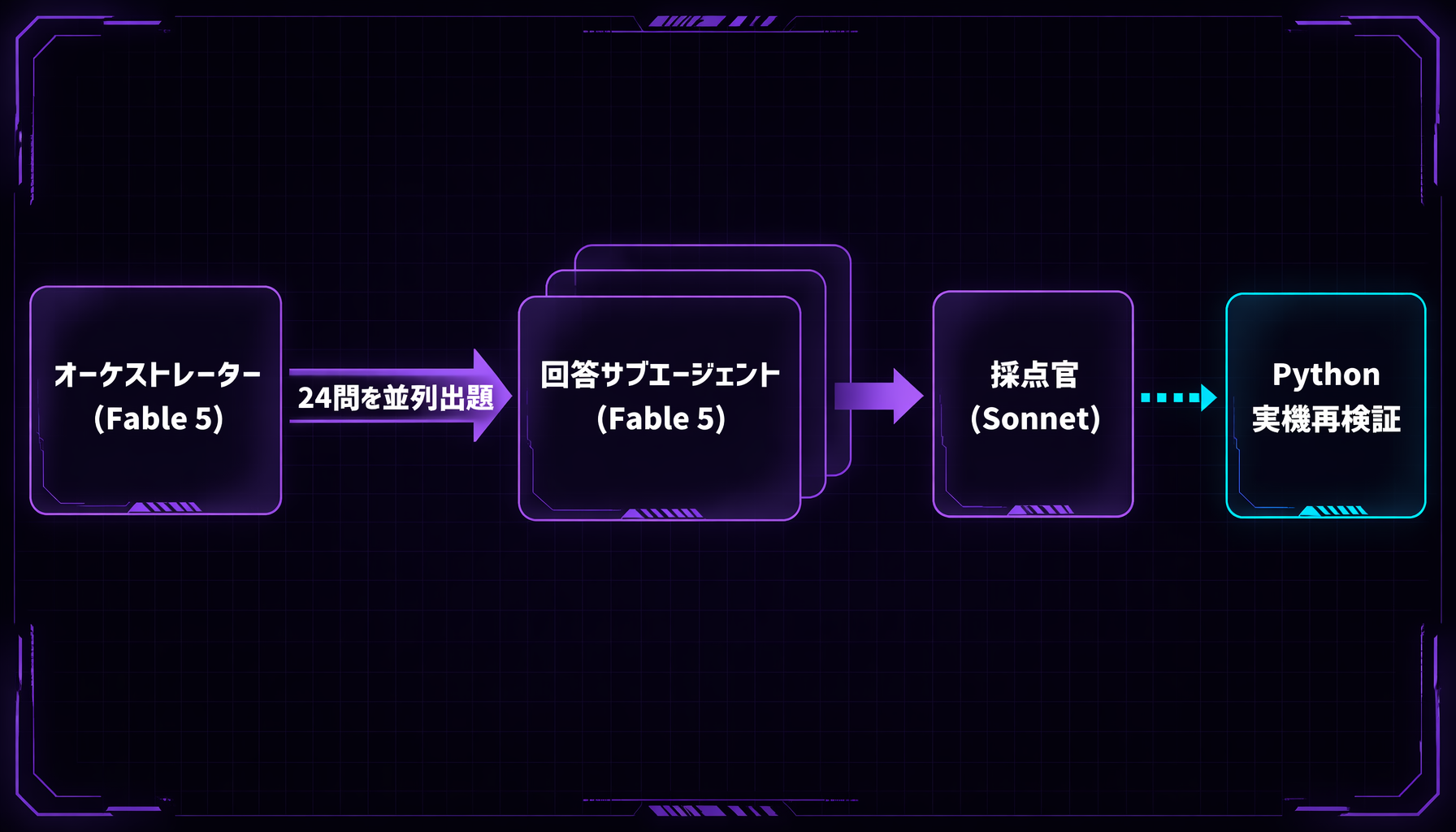
検証構成: 出題・回答・採点・再検証を別々の役割に分離した(回答者と採点官は別モデル)
この開示は大事です。自己ベンチマークは、やり方を隠すとほぼ意味がありません。どう測ったかが分からない点数は、判断材料として弱い からです。
24問ベンチマークの見え方は、僅差でもまるで違う
今回の Fable 5 と Haiku 4.5 は、総点では 224 対 221 と僅差です。でも、実際の使い心地を想像すると、かなり違うはずです。
Fable 5 は、
- 論理の深い問題をきれいに通す
- 既存の正解集の誤りを見つける
- ただし曖昧文の直感誤答は残す
Haiku 4.5 は、
- 一部の問題で総崩れする
- ただし別の領域では同じ点数まで持っていく
つまり、僅差なのに別物です。これは総点ベンチマークの限界そのものです。
参考になる比較:24問解説、Haiku+Advisor、Bonsai-8B
今回の続きとして読むなら、以下の3本がつながります。
- 24問の設計そのものを知りたいなら: /blog/local-llm-benchmark-24-questions-explained
- Haiku+Advisor の流れを追いたいなら:
 Blog格安モデルでも Rank S:Haiku 4.5 × 24問テスト実測(+Advisor で97.5%)Haiku 4.5を24問で実測。単体93%でも十分強く、Advisor(Opus)の2パスで97.5%まで改善。ただし自信満々に間違える盲点も見えました。→
Blog格安モデルでも Rank S:Haiku 4.5 × 24問テスト実測(+Advisor で97.5%)Haiku 4.5を24問で実測。単体93%でも十分強く、Advisor(Opus)の2パスで97.5%まで改善。ただし自信満々に間違える盲点も見えました。→ - 低コスト側の比較を見たいなら:
 BlogBonsai 8B実測:世界初の1-bit LLMはなぜランクCか——24問で見えた用途Bonsai-8Bの24問実機ベンチマークを実測。1.15GBの軽さ、コード満点、日本語文化壊滅という二面性を、用途別に正直に整理します。→
BlogBonsai 8B実測:世界初の1-bit LLMはなぜランクCか——24問で見えた用途Bonsai-8Bの24問実機ベンチマークを実測。1.15GBの軽さ、コード満点、日本語文化壊滅という二面性を、用途別に正直に整理します。→
Claude 製品同士を無理に持ち上げるつもりはありません。ですが、どこで差が出て、どこでは差が出ないか を見るには、こういう並びが役に立ちます。
よくある質問
Q. じゃあ Fable 5 は Opus 4.8 から乗り換える価値がありますか?
用途次第です。少なくとも今回の24問では、最上位らしい強さはありました。特に論理問題とバグ発見は強いです。ただし、A4 のような曖昧文の誤答は残ります。なので、「何でも正しくなる」モデルではありません。
Q. 6/22 まで無料なら、とりあえず試すべきですか?
Claude Code ユーザーなら、試す価値はあります。特に、コードレビュー、根拠付きの推論、既存成果物の矛盾チェックをよくやるなら、差が見えやすいです。逆に、単発の雑談や軽い要約中心なら、料金差に見合うかは微妙です。
Q. 総点224点は信じていいですか?
参考にはなりますが、鵜呑みにはしないほうがいいです。今回のように、合計が僅差でも中身は違いますし、採点官のブレもあります。総点は入口、実例は判断材料です。
Q. C6 の正解集バグはモデルのミスではないのですか?
いいえ、今回は逆です。モデルが正しく、正解集が間違っていました。 その発見自体が、Fable 5 の実力を示しています。
Q. 公式の高いベンチマークも見たほうがいいですか?
はい。ただし、今回の記事では未確認の二次情報は採用していません。公式ベンチや発表資料は参考になりますが、自分の用途に近い実測とセットで見るのが安全です。
参考リンク
- 公式発表: https://www.anthropic.com/news/claude-fable-5-mythos-5
- 24問解説: /blog/local-llm-benchmark-24-questions-explained
- Haiku+Advisor 記事: Blog格安モデルでも Rank S:Haiku 4.5 × 24問テスト実測(+Advisor で97.5%)Haiku 4.5を24問で実測。単体93%でも十分強く、Advisor(Opus)の2パスで97.5%まで改善。ただし自信満々に間違える盲点も見えました。→
- Bonsai-8B 記事: BlogBonsai 8B実測:世界初の1-bit LLMはなぜランクCか——24問で見えた用途Bonsai-8Bの24問実機ベンチマークを実測。1.15GBの軽さ、コード満点、日本語文化壊滅という二面性を、用途別に正直に整理します。→
- 提供条件・API仕様: https://platform.claude.com/docs/en/about-claude/models/introducing-claude-fable-5-and-claude-mythos-5
- サブスク提供期間の報道: https://techcrunch.com/2026/06/09/anthropic-released-claude-fable-5-its-most-powerful-model-publicly-days-after-warning-ai-is-getting-too-dangerous/
まとめ:Fable 5 は「僅差なのに別物」だった
最後に、今回の判断材料を一行でまとめます。
Fable 5 は24問ベンチで 224/240、Haiku 4.5(221/240)をわずかに上回りました。 ただし、B6 では Haiku が崩れた最難問を完答し、C6 では正解集のバグまで見つけました。一方で A4 のりんご問題では、Haiku と同じ誤答をしました。
なので結論は単純です。Fable 5 は強い。でも総点だけで判断すると見誤る。
無料期間中に触るなら、まずは自分の実務に近い少数の問題で試してください。コード、仕様、レビュー、曖昧文の解釈。そこで何が伸びて、何が残るかを見るのがいちばん確実です。
注意点・制約
- スコアはテスト設計と採点基準に依存します。他のベンチマークと単純比較はできません。
- LLM採点には±5点程度の判定ブレがあります。1〜2問差での優劣判断は避けてください。
- 料金・提供条件は2026-06-10時点のものです。6/23以降は条件が変わるため、最新の公式情報を確認してください。
- 自分の用途で試すまで、スコアだけで導入を決めないほうが安全です。
この記事は、実務で AI ツールを活用している開発者・技術者向けに書いています。
この記事を書いた人
HW系エンジニアとして20年以上、10,000件を超える顧客訪問と2,000件を超える単独ソリューション実績。AIツールを使った個人開発やIoT農園など、Raspberry Piを使ったオートメーション化なども実践中です。エンジニア専門結婚相談所も運営中です。ClaudeCodeで解決できない心の課題も、現場目線で一緒に整理します。
関連記事
 BlogAnthropicリーク2連発:Claude MythosとClaude Code流出で見えたKAIROS、BUDDY、Undercover Modeの正体Anthropicの2週間で2回のリークを整理。Claude Mythosの位置づけ、Claude Code流出の中身、KAIROS/BUDDY/Undercover Modeの意味を分けて読む。→
BlogAnthropicリーク2連発:Claude MythosとClaude Code流出で見えたKAIROS、BUDDY、Undercover Modeの正体Anthropicの2週間で2回のリークを整理。Claude Mythosの位置づけ、Claude Code流出の中身、KAIROS/BUDDY/Undercover Modeの意味を分けて読む。→ BlogClaude Opus 4.8 は何が変わった?ベンチより「正直さ」と並列エージェントが本命だったClaude Opus 4.8 で本当に変わったのは、ベンチの数ポイントではなく『正直さ』と並列サブエージェントでした。公式ベンチ、4つの新機能、OpenRouter の実トラフィックを重ねて、価格据え置きの今回のアップデートを乗り換え目線で整理します。→
BlogClaude Opus 4.8 は何が変わった?ベンチより「正直さ」と並列エージェントが本命だったClaude Opus 4.8 で本当に変わったのは、ベンチの数ポイントではなく『正直さ』と並列サブエージェントでした。公式ベンチ、4つの新機能、OpenRouter の実トラフィックを重ねて、価格据え置きの今回のアップデートを乗り換え目線で整理します。→
META-MARK × AI
ローカルAIを動かすGPU、ちゃんと選べていますか?
VRAM・性能・コスパをMetaScoreで数値化。AIアプリ別の推奨ハードウェア要件も確認できます。